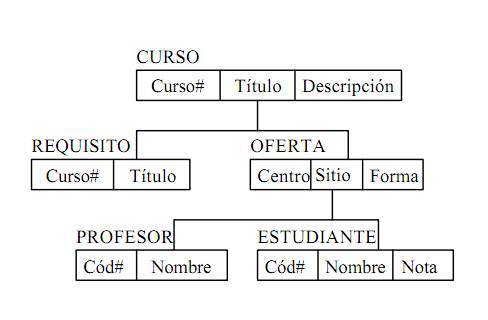
TERCERA FORMA NORMAL
La regla de la Tercera Forma
Una tabla está normalizada en esta forma si todas las columnas que no son llave son funcionalmente dependientes por completo de la llave primaria y no hay dependencias transitivas. Una dependencia transitiva es aquella en la cual existen columnas que no son llave que dependen de otras columnas que tampoco son llave.
Cuando las tablas están en la Tercera Forma